Metadata
- Author: ActivitySchema
- Full Title:: New in Activity Schema 2.0
- Category:: 🗞️Articles
- URL:: https://github.com/ActivitySchema/ActivitySchema/blob/main/2.0.md
- Finished date:: 2023-04-07
Highlights
Reached to it from a a Benn Stancil article, The Rapture and the Reckoning, and he is way against it:
Link to originalA few years ago, Narrator, a product inspired by tools inside of WeWork, proposed a design pattern that they called the activity schema. If nothing else, I give it points for audacity: The entire blueprint is one giant event table. It’s as if you took a star schema, joined every dimension table onto its corresponding fact table, and then unioned all of those fact tables together into one bottomless list of events. (View Highlight)
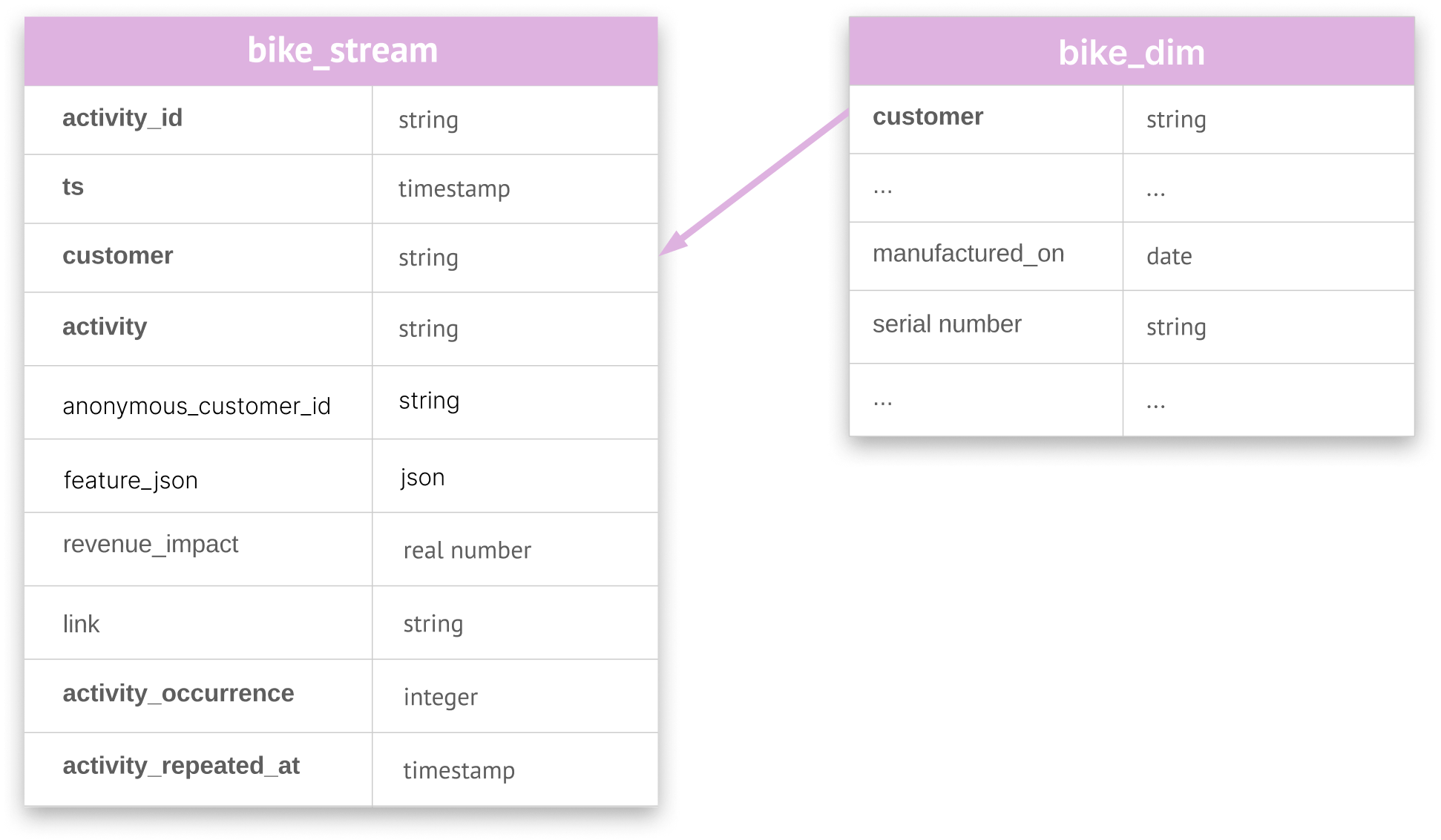
An activity schema table will only have one entity type and is typically named
<entity>_stream. For example, an activity schema implementation for customers would becustomer_stream, and one for bikes would bebike_stream(View Highlight)
Because an activity is a specific event that happened at a moment in time, for data modeling purposes it’s immutable. An activity should never change (View Highlight)
Every activity has metadata associated with it beyond the customer, the activity, and the timestamp. A ‘viewed page’ activity will want to store the actual page viewed, while an ‘invoice paid’ activity will store the total amount paid (View Highlight)
The entity table (typically called
<entity>_dim) stores metadata for each entity. (View Highlight)
 (
(The choice to use a single activity table or multiple is mostly implementation and warehouse-dependent. For example, it can be easier to build one table per activity, but it’s slightly harder to query. (View Highlight)
feature_json Activity-specific features JSON (View Highlight)
The activity stream table is designed for fast queries on common data warehouses like Redshift, BigQuery, and Snowflake (View Highlight)
But weren’t self joins actually harmful?
In addition, the activity stream table typically only needs to be joined with itself when queried, which further increases performance over other modeling approaches. (View Highlight)
The primary key column is the only required column and by convention is always named customer — the same name as the corresponding column in the activity stream. ****It must store the same entity identifier as the activity stream. (View Highlight)
Not all raw tables are modeled directly. Instead of thinking about what to do with each raw table, it helps to first identify which activities make sense (View Highlight)
An activity schema does not require any foreign key joins. All joins are self-joins to th (View Highlight)
e activity_stream table, and they only use the entity and timestamp columns. This means there is always a way to relate any data in an activity schema to anything else. (View Highlight)