
Metadata
- Author: anthropic.com
- Full Title:: Introducing Contextual Retrieval
- Category:: 🗞️Articles
- Document Tags:: Foundational models, RAG
- URL:: https://www.anthropic.com/news/contextual-retrieval?ref=blef.fr
- Read date:: 2024-12-26
Highlights
Sometimes the simplest solution is the best. If your knowledge base is smaller than 200,000 tokens (about 500 pages of material), you can just include the entire knowledge base in the prompt that you give the model, with no need for RAG or similar methods. (View Highlight)
While embedding models excel at capturing semantic relationships, they can miss crucial exact matches. Fortunately, there’s an older technique that can assist in these situations. BM25 (Best Matching 25) is a ranking function that uses lexical matching to find precise word or phrase matches. It’s particularly effective for queries that include unique identifiers or technical terms. (View Highlight)
BM25 works by building upon the TF-IDF (Term Frequency-Inverse Document Frequency) concept. TF-IDF measures how important a word is to a document in a collection. BM25 refines this by considering document length and applying a saturation function to term frequency, which helps prevent common words from dominating the results. (View Highlight)
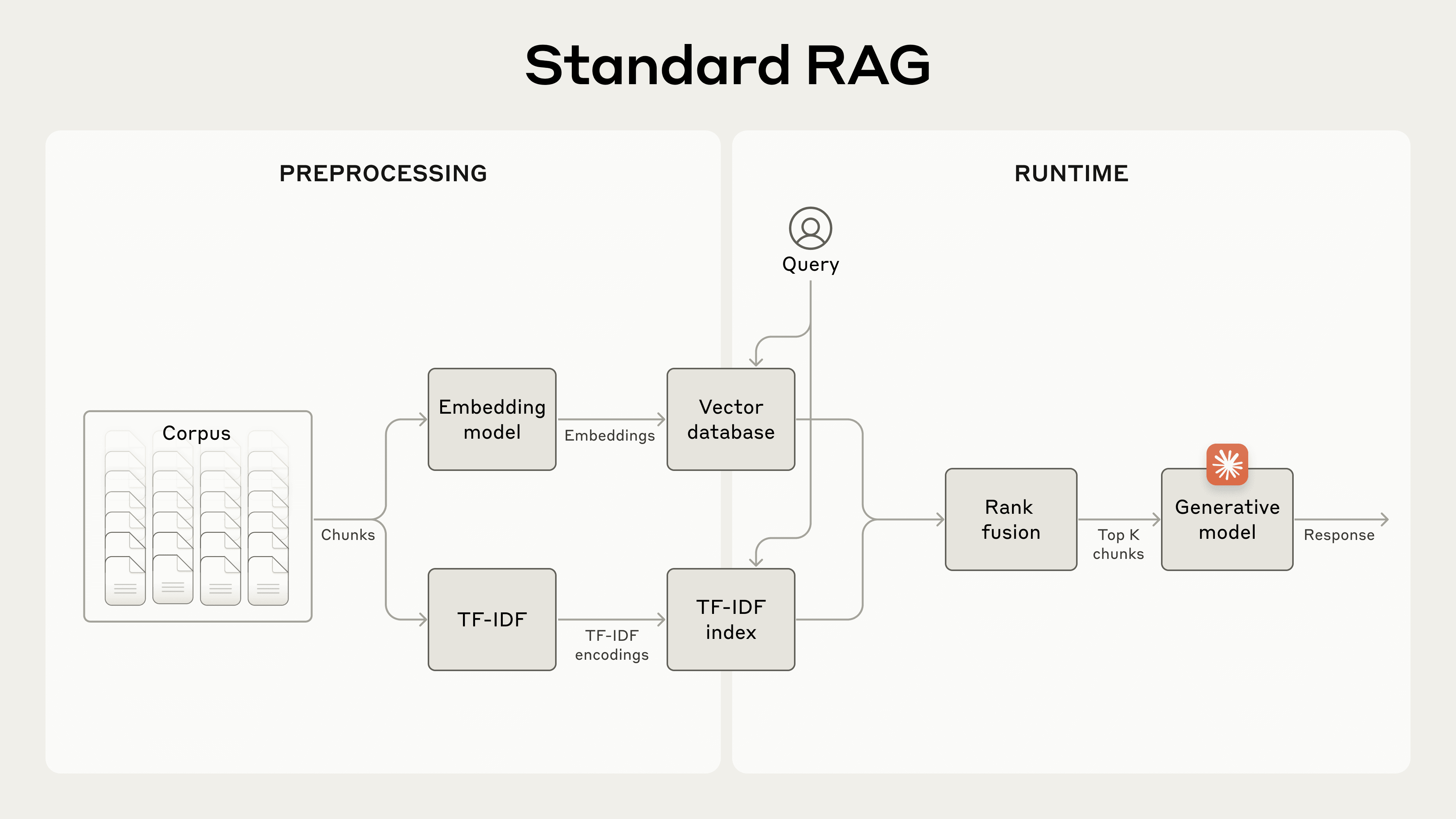
RAG solutions can more accurately retrieve the most applicable chunks by combining the embeddings and BM25 techniques using the following steps:
- Break down the knowledge base (the “corpus” of documents) into smaller chunks of text, usually no more than a few hundred tokens;
- Create TF-IDF encodings and semantic embeddings for these chunks;
- Use BM25 to find top chunks based on exact matches;
- Use embeddings to find top chunks based on semantic similarity;
- Combine and deduplicate results from (3) and (4) using rank fusion techniques;
- Add the top-K chunks to the prompt to generate the response. (View Highlight)
 (
(these traditional RAG systems have a significant limitation: they often destroy context. (View Highlight)
Contextual Retrieval solves this problem by prepending chunk-specific explanatory context to each chunk before embedding (“Contextual Embeddings”) and creating the BM25 index (“Contextual BM25”). (View Highlight)
Other proposals include: adding generic document summaries to chunks (we experimented and saw very limited gains), hypothetical document embedding, and summary-based indexing (we evaluated and saw low performance). (View Highlight)
Of course, it would be far too much work to manually annotate the thousands or even millions of chunks in a knowledge base. To implement Contextual Retrieval, we turn to Claude. (View Highlight)
Contextual Retrieval is uniquely possible at low cost with Claude, thanks to the special prompt caching feature we mentioned above. With prompt caching, you don’t need to pass in the reference document for every chunk. You simply load the document into the cache once and then reference the previously cached content. (View Highlight)
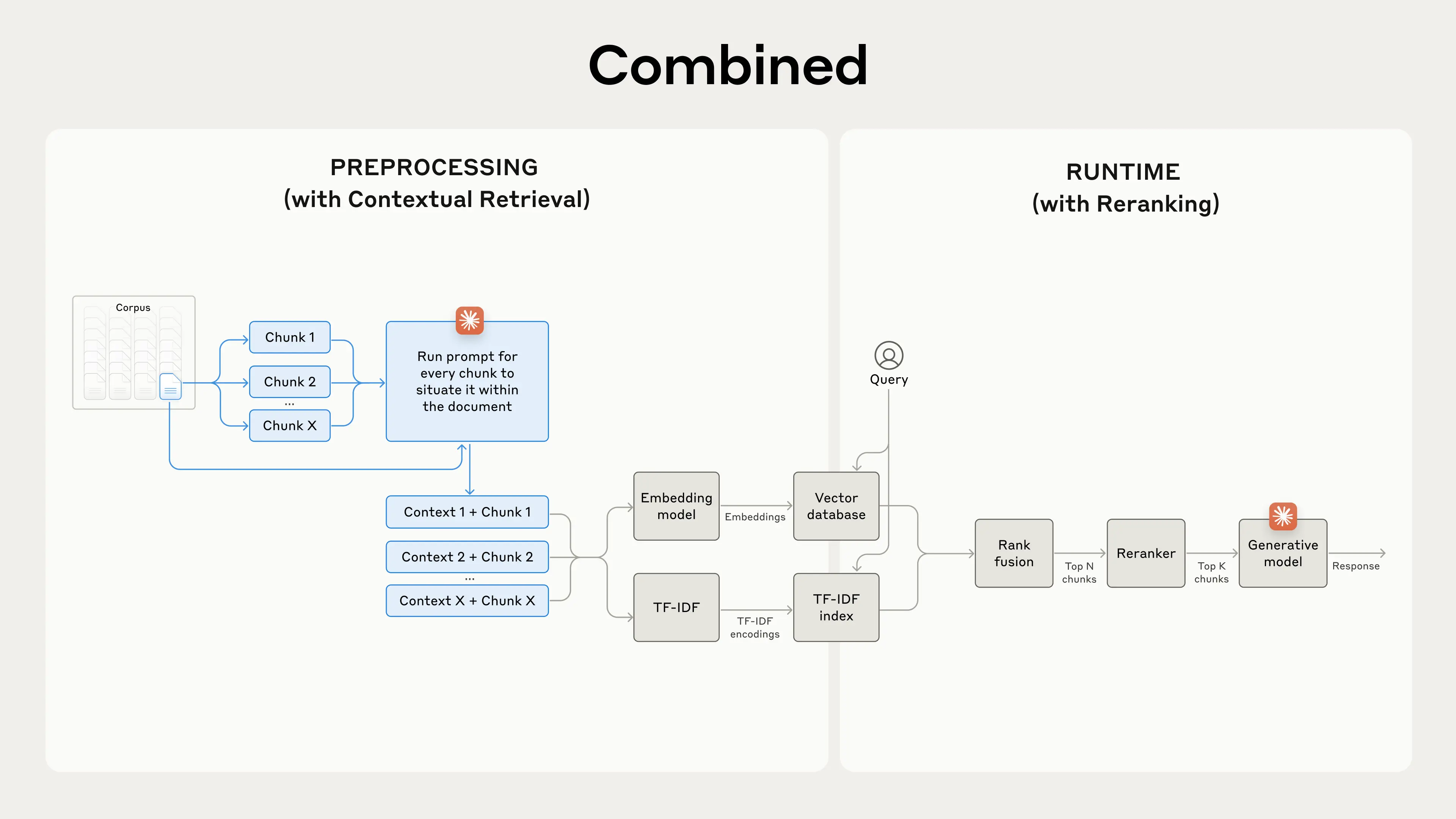 (
(There are several reranking models on the market. We ran our tests with the Cohere reranker. Voyage also offers a reranker, though we did not have time to test it. Our experiments showed that, across various domains, adding a reranking step further optimizes retrieval. (View Highlight)