Metadata
- Author: Mikkel Dengsøe
- Full Title:: Data Team Structure: Embedded or Centralised?
- Category:: 🗞️Articles
- Document Tags:: data team topologies
- URL:: https://mikkeldengsoe.substack.com/p/data-team-structure-embedded-or-centralised?s=r
- Finished date:: 2023-05-02
Highlights
Getting this right (if there’s such a thing as right here) is no small deal as a lot of things will fall in or out of place depending on how you set your team (View Highlight)
The key here is that usually Data Engineers are “classic Data Engineers” + “Analytics Engineers”.
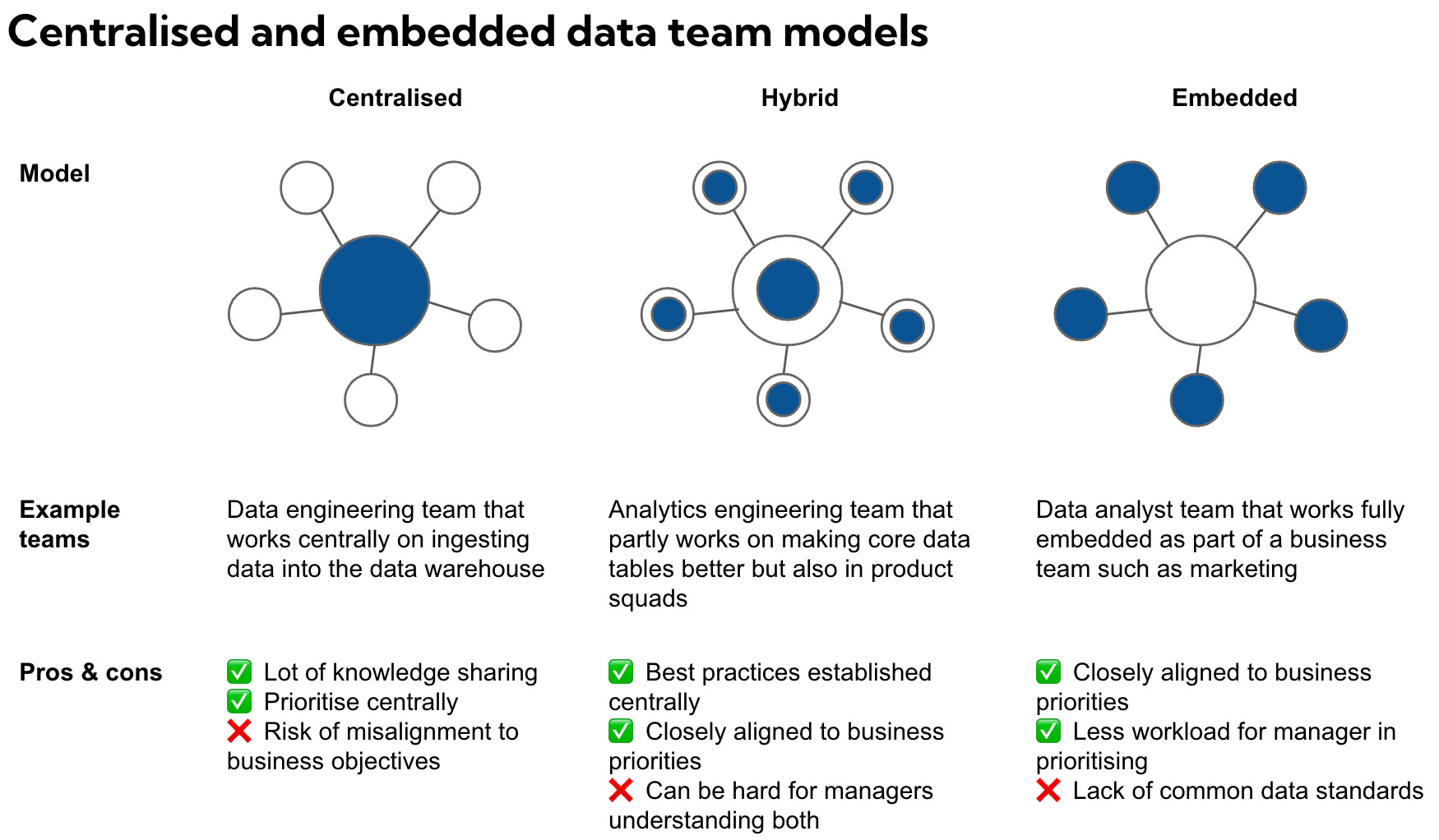
Some teams naturally tie themselves to being centralised. Data engineers for example benefit from working on shared objectives such as improving data pipelines or tooling. Analysts with domain expertise in credit modelling may tie themselves better to being fully embedded and working as part of a business function. But for data analysts, data scientists and analytics engineers the answer is less clear. (View Highlight)
This is key as well: there is not a fixed model. At an early stage it’s not the same than when you have 10 DEs (if you have them).
In reality you’ll often have to alternate between the two models and what worked well six month ago may no longer be the right model if the team or priorities have changed. (View Highlight)
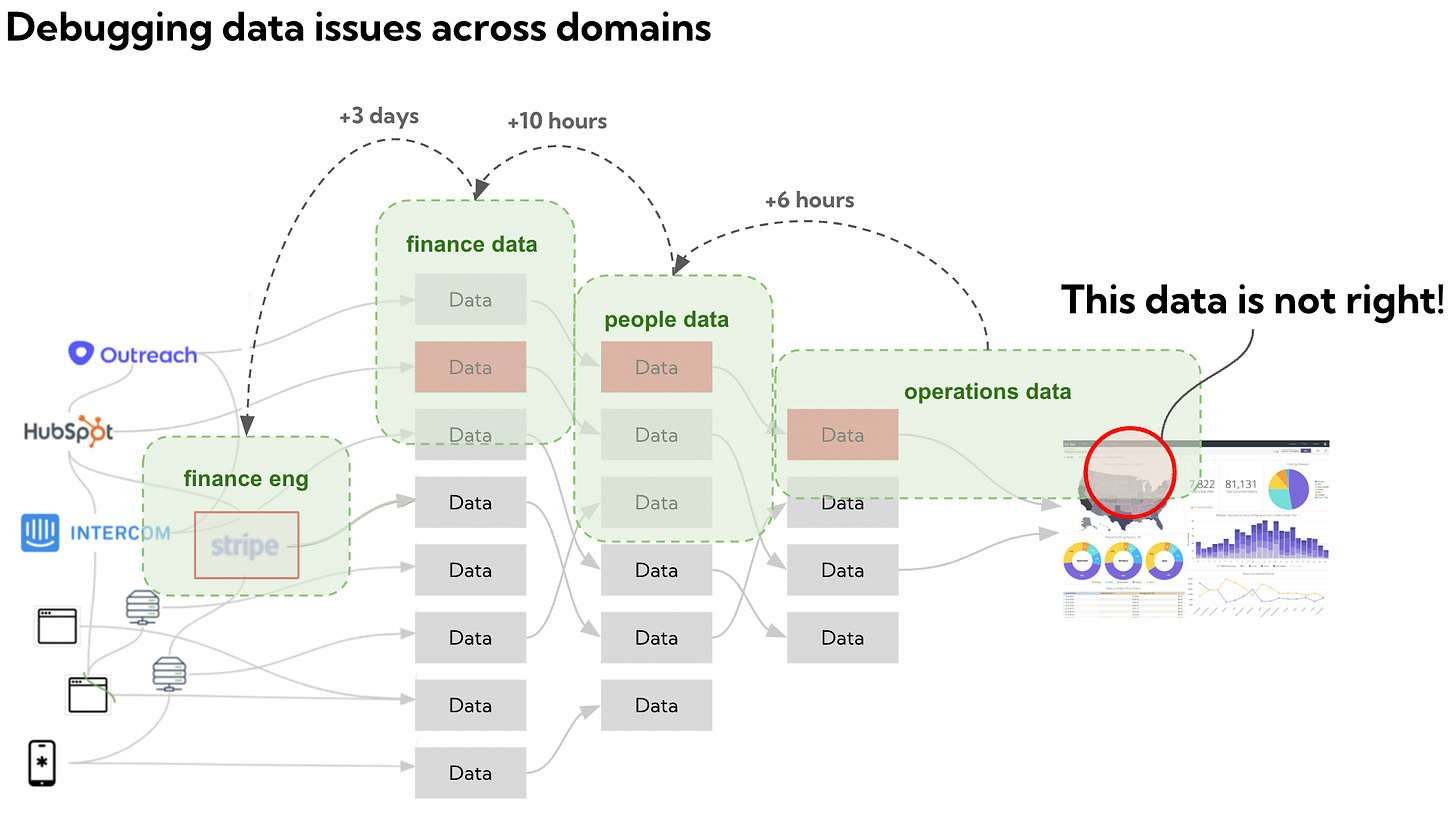
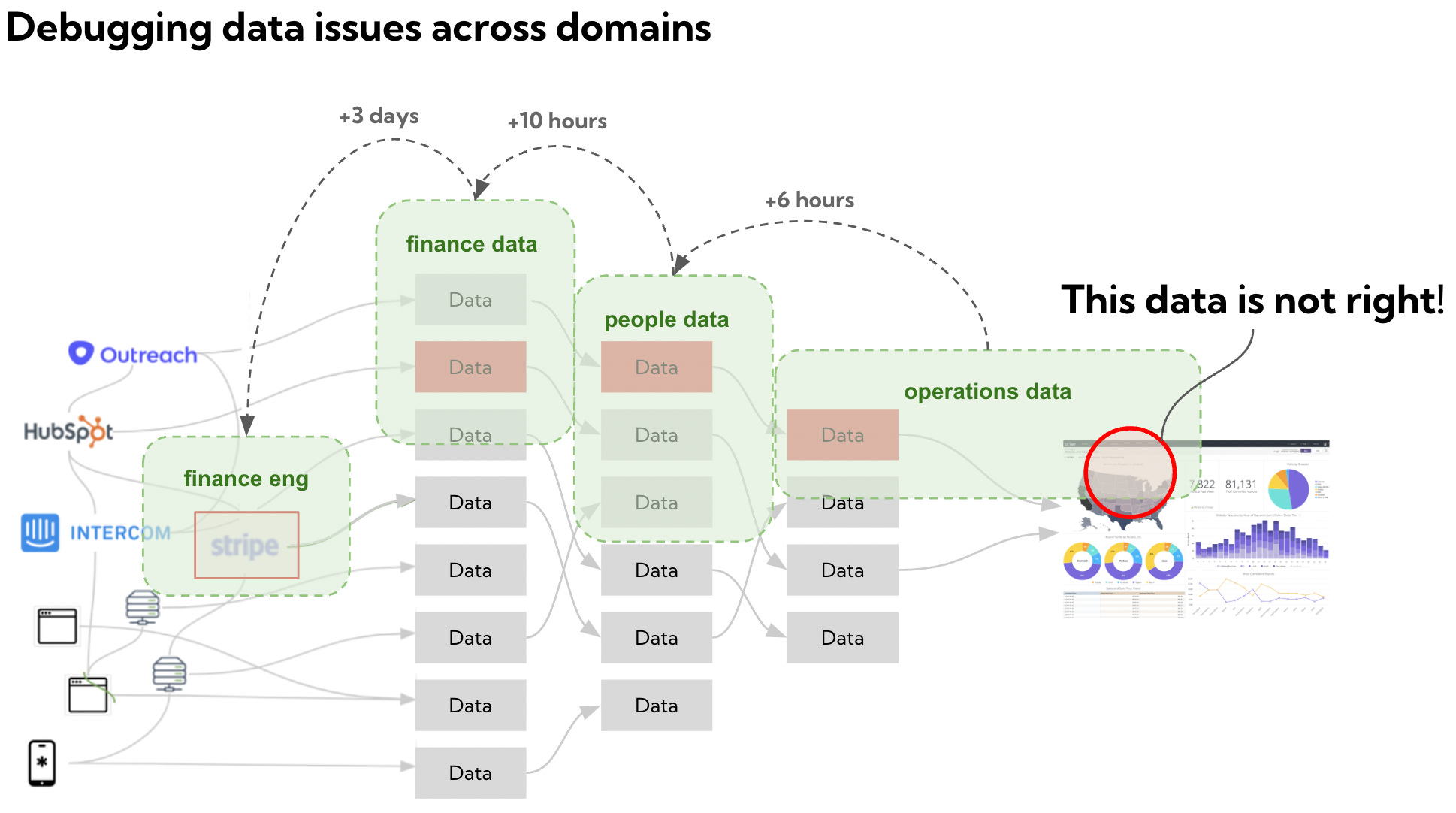
But that change in data should be owned by that very same engineer, and detected by her team in the data set they are offering to others.
A not too uncommon scenario starts with an engineer making a change in a backend microservices that causes a metric to be wrong downstream in a Looker dashboard. For the engineer this is a small fix and can be reverted in 5 minutes. For the data team this could mean days of work to uncover. (View Highlight)
 (
({kind=link}